01 / 03
Vos données fuient vers les États-Unis
ChatGPT, Claude, Gemini : tout passe par AWS, GCP ou Azure. Le Cloud Act autorise les autorités fédérales à demander vos prompts. Le DPA ne protège pas — la juridiction US le surcharge.

Le coq français de l'IA souveraine
Serveurs en France et en Allemagne. Modèles open-source figés sur nos GPU, jamais d'appel externe. Chiffrement post-quantique inclus. Prix fixe par entreprise — pas de pay-per-token.
Trois douleurs des décideurs
01 / 03
ChatGPT, Claude, Gemini : tout passe par AWS, GCP ou Azure. Le Cloud Act autorise les autorités fédérales à demander vos prompts. Le DPA ne protège pas — la juridiction US le surcharge.
02 / 03
Article 12 : traçabilité par requête. Les dashboards américains ne suivent pas vos exigences. Vos contrôleurs CNIL et autorités de marché vous tiennent responsable, pas votre fournisseur.
03 / 03
Pay-per-token : à 0,002 €/1K tokens, c'est cheap au démarrage. Trois mois plus tard, la facture explose. Aucun levier de négociation. Aucune ligne budgétaire fixe possible.
Notre réponse
Pas de modèle américain rebadgé. Pas de chiffrement marketing. Pas de prix variable. Une plate-forme conçue pour résister à dix ans d'audit ANSSI.
Hetzner (Allemagne), Scaleway (Paris), OVHcloud (Roubaix). Aucune dépendance AWS, GCP, Azure. Aucune télémétrie sortante. Cloud Act inopposable.
0
octet hors UE
Premier SaaS IA UE à shipper 4 couches PQC en production. ML-KEM-768 hybride, X25519MLKEM768 TLS, SLH-DSA-128f sur audit log. Inclus baseline sur toutes les offres.
NIST 203/205
FIPS · 4 couches
Pas de pay-per-token. Pas de surprise sur facture. Fair-use budgétaire invisible (20 % du prix), fallback automatique vers modèle léger si saturation. Une ligne budgétaire annuelle.
299 € — 2 500 €+
par mois · HT
MEGA plus-value n°1 · le cerveau
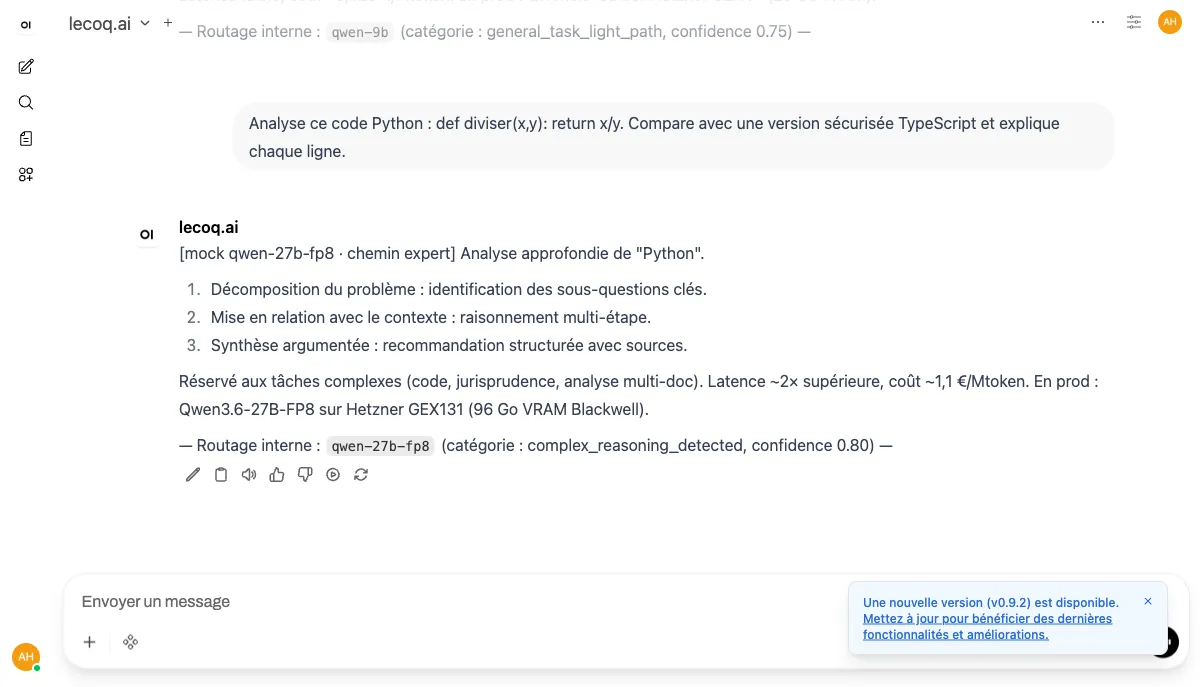
Une question simple n'a pas besoin d'un modèle géant. Un dossier juridique de 200 pages, si. Auriga lit chaque requête, analyse quatre dimensions critiques en moins de 20 ms, et choisit le moteur d'inférence le plus pertinent. Vous gagnez en latence, en coût et en précision — sans jamais avoir à choisir un modèle vous-même.
Schéma fonctionnel · décision serveur, jamais exposée au client
Quatre signaux. Une décision.
Résumé simple ? Raisonnement multi-étape ? Le classifieur tranche en moins de 20 ms.
Code, juridique, RH, médical… Détection métier pour activer le bon contexte RAG.
Tentative d'injection ou de jailbreak ? Bloquée avant même d'atteindre un modèle.
PII détectées en temps réel. Anonymisation ou refus selon la politique tenant.
< 20 ms
Décision de routage
Classifieur mmBERT spécialisé, embarqué dans la gateway. Pas d'aller-retour réseau, pas de modèle géant qui décide.
~ 4×
Économie d'inférence
En routant 80 % du trafic sur le modèle léger, vous économisez l'équivalent de trois modèles experts qui tourneraient pour rien.
0
Choix exigé du client
Vos collaborateurs ne voient qu'un seul modèle nommé lecoq.ai. Le routage est invisible, infalsifiable côté serveur.
Auriga s'appuie sur vLLM Semantic Router v0.2 Athena (mmBERT + LoRA, code open-source) couplé à LiteLLM Gateway pour le contrôle budgétaire et la traçabilité AI Act Article 12. Aucune brique américaine sur le chemin critique d'inférence.
MEGA plus-value n°2 · le coffre-fort
La plupart des fournisseurs vous demandent de leur faire confiance. Nous prouvons cryptographiquement que la confiance est superflue. Trois datacenters européens, quatre garanties non-négociables, et la défense contre l'ordinateur quantique de demain — dès aujourd'hui.
Là où vivent vos données
Deux tiers de notre capacité en France. Le reste en Allemagne. Aucune dépendance aux hyperscalers américains.
Hetzner · Falkenstein, Allemagne
Base load 24/7 — GPU expert
OVHcloud · Roubaix, France
Vault HSM + SecNumCloud 3.2
Scaleway · Paris, France
Scale-out horaire
Quatre garanties non-négociables
Hetzner Falkenstein, Scaleway Paris, OVHcloud Roubaix. Aucun cloud américain. Cloud Act inopposable.
Pas de télémétrie sortante, pas de SDK analytics, pas de DPA tiers à signer. Vos données restent dans la base PostgreSQL chiffrée de votre tenant.
Modèles Qwen open-source téléchargés une fois, figés par leur SHA, servis tels quels. Vos requêtes alimentent l'inférence — jamais l'entraînement.
Code Rust audité, dépendances open-source pinnées, logs immuables 5 ans. Auditabilité PASSI / SecNumCloud sur Gouvernance.
Cryptographie post-quantique
Un attaquant patient capture aujourd'hui votre trafic chiffré classique (RSA, ECDH). Quand l'ordinateur quantique cryptographiquement pertinent émerge — NIST estime entre 2030 et 2040 — il déchiffre tout. Quatre couches NIST FIPS 203/205 actives en production, par défaut, pour tous nos clients.
01
TLS hybride transport
X25519MLKEM768
NIST FIPS 203
02
Chiffrement des données au repos
ML-KEM-768 + X25519
NIST FIPS 203
03
mTLS interne Postgres / Redis
X25519MLKEM768
NIST FIPS 203
04
Signature audit log plate-forme
SLH-DSA-128f
NIST FIPS 205
Un audit RSSI ou ANSSI peut prouver l'activation immédiatement, sans accès SSH, sans NDA. Une commande terminal suffit.
openssl s_client -groups X25519MLKEM768 -connect lecoq.ai:443
Compatible Chrome 131+, Firefox 132+, Safari iOS 26+. Fallback X25519 transparent.
Pour qui ce n'est pas négociable
Cabinets juridiques
10-20 ans
Notaires
75 ans
Expert-comptables
10 ans
Santé
20 ans
BITD défense
30+ ans
Public ANSSI
50+ ans
Côté
Concurrents non-UE
leaders mainstream avril 2026
Critère
Garantie objective
lecoq.ai
Notre engagement
Hébergement & juridiction
Données hors UE possibles
100 % UE, Cloud Act inopposable
Cryptographie post-quantique
Roadmap, parfois en option payante
4 couches FIPS 203/205, baseline toutes offres
Entraînement sur vos prompts
Opt-out parfois payant ou contractuel
Modèles open-source figés, pinning par SHA
Coût mensuel
Pay-per-token, dérive imprévisible
Forfait fixe entreprise, fair-use transparent
Auditabilité PASSI
Souvent indisponible ou complexe
Offre Gouvernance SecNumCloud 3.2
Coûts maîtrisés
Le pay-per-token est un mensonge tarifaire qui transfère le risque chez vous. Notre offre Essentiel à 299 €/mois équivaut à environ 120 heures de chat cumulées pour 20 employés. Un budget IT se planifie en ligne fixe annuelle. Nous tenons cette promesse.
Économies sur 12 mois
0 €
vs concurrent pay-per-token typique pour 20 employés
0 %
marge brute cible
0 %
plancher hard stop
Coût mensuel comparé
Modèle illustratif basé sur usage croissant typique d'une PME. Concurrent simulé à 0,002 €/1K tokens, croissance d'usage 8 % mensuel après 90 jours.
Sobriété par design
~80 % de GPU économisé
Le moteur Auriga route 80 % du trafic vers le modèle léger. Le 27B-FP8 ne tourne que pour les requêtes qui le méritent. Cache sémantique Redis pour les questions répétées : 0 GPU consommé.
~80 %
GPU économisé / requête
0 €
scale-to-zero nuit + week-end
GreenIT par sobriété
Notre routeur sémantique tranche en 20 ms : 80 % du trafic part sur un modèle léger, l'expert n'est sollicité qu'au juste besoin. Cache sémantique Redis : une question répétée renvoie la réponse précédente sans appel GPU.
Démo en conditions réelles
Vos employés voient un seul modèle lecoq.ai. En interne, notre routeur sémantique choisit en moins de 20 ms entre un modèle léger (résumés, traductions) ou un modèle expert (raisonnement profond, code, juridique). Le badge final dévoile la décision pour la traçabilité AI Act Article 12.
Tarification
Trois offres calibrées pour des entreprises qui ne veulent pas réveiller leur DAF chaque trimestre. Le quota équivalent en heures de chat est volontairement surdimensionné.
TPE et petites équipes — IA souveraine sans complexité.
PME et départements ETI — routage complet, RAG illimité, SSO.
ETI, secteur public, santé, défense — SecNumCloud, BYOK HSM, audit eIDAS.
3 paliers : Base · Premium TDX · Sovereign
Garantie 30 jours satisfait-ou-remboursé. Engagement annuel : -15 %. Pas de remise au-delà.
Pour qui
Pour ces métiers, le contenu protégé doit le rester pendant des décennies. Le pas-encore-quantique de 2026 sera un menteur de 2030.
Secret professionnel déontologique
Code civil — actes authentiques
Code de commerce — pièces
RGPD + secret médical
Instruction interministérielle 901
ANSSI · classification
Validation technique
Couche 1 — TLS hybride
NIST FIPS 203$ openssl s_client \
-groups X25519MLKEM768 \
-connect lecoq.ai:443
→ Negotiated TLS1.3 with
X25519MLKEM768Codepoint IANA 0x11ec. Compatible Chrome 131+, Firefox 132+, Safari iOS 26+. Fallback X25519 transparent pour anciens browsers.
Couche 2 — Wrap KEK app-layer
NIST FIPS 203$ psql tenant_airetvie -c \
"SELECT octet_length(chat_dek_wrapped)
FROM chat;"
octet_length
─────────────
1181Format wire : 1 (version) + 1088 (mlkem-768 ct, k=3) + 32 (x25519) + 12 (nonce) + 48 (aes-gcm). Conformité NIST FIPS 203 vérifiable byte par byte.
Couche 4 — Audit log signé
NIST FIPS 205$ verify-audit-chain \
--since 7d
→ HMAC chain OK (124 rows)
→ SLH-DSA verify OK
signature ~17 KB / rowCron K8s hebdomadaire (dimanche 04:00 UTC). Chaîne HMAC + signature SLH-DSA-128f. Toute divergence = alerte P1 + escalation cofondateurs.
Modèles open-weights pinnés
Apache 2.0chemin léger:
Qwen/Qwen3.5-9B
served-model-name: qwen-9b
chemin expert:
Qwen/Qwen3.6-27B-FP8
served-model-name: qwen-27b-fp8
→ Téléchargés une fois
→ Pinnés par SHA
→ Aucun fine-tuning sur vos donnéesAudit cryptographique expert disponible sur demande · Lire la documentation technique
Questions fréquentes
Lancement officiel S2 2026
Programme pilote ouvert à 3 entreprises beta sur le second semestre 2026. Tarif préférentiel -50 % en échange d'un témoignage public à la GA.
Aucun engagement · Réponse sous 48h ouvrées · equipe@lecoq.ai